DeepAugment¶

Find optimal image augmentation policies for your dataset automatically. DeepAugment uses Bayesian optimization to discover augmentation strategies that maximize model performance.
Quick Start¶
Installation¶
pip install deepaugment
or using uv:
uv add deepaugment
Simple API¶
from deepaugment import optimize
best_policy = optimize(my_images, my_labels, iterations=50)
Basic Usage (CIFAR-10)¶
from torchvision.datasets import CIFAR10
from deepaugment import optimize
import numpy as np
train_data = CIFAR10(root='./data', train=True, download=True)
X = np.array(train_data.data)[:5000] # Use subset for speed
y = np.array(train_data.targets)[:5000]
best_policy = optimize(X, y, iterations=50)
Advanced Usage¶
from deepaugment import DeepAugment
# Separate train/validation sets
aug = DeepAugment(X_train, y_train, X_val, y_val,
n_operations=4, # transforms per policy
train_size=2000, # subset for speed
val_size=500)
# Optimize
best = aug.optimize(iterations=50, epochs=10)
# Show results
aug.show_best(n=5)
Why DeepAugment?¶
Uses Bayesian Optimization instead of Reinforcement Learning, requiring ~100x fewer iterations than AutoAugment.
Optimize CIFAR-10 policies in 4.2 hours for ~$13 on AWS p3.x2large (vs. days/weeks for AutoAugment).
60% error reduction (8.5% accuracy increase) on CIFAR-10 with WRN-28-10.
User-friendly API with extensive configuration options. Bring your own model or use built-in ones.
Key Features¶
- 🎨 26 Modern Transforms
Geometric, color, blur, noise, occlusion, and advanced transforms from torchvision v2.
- 🧠 Smart Optimization
Bayesian Optimization with Random Forest Estimator and Expected Improvement acquisition.
- ⚡ Minimal Child Model
Fast training (~30 seconds per iteration on V100 GPU) with 1.2M parameters.
- 🔬 Scientific Rigor
Published method with DOI, reproducible results, and comprehensive documentation.
Documentation¶
User Guide
Examples
API Reference
How It Works¶
DeepAugment has three major components:
Controller: Samples new augmentation policies using Bayesian Optimization
Augmenter: Transforms images according to the policy
Child Model: Trains from scratch on augmented images and returns a reward

The controller iteratively: - Samples new policies based on previous results - Evaluates them using the child model - Updates its surrogate model - Repeats until convergence or max iterations
Results¶
CIFAR-10 best policies tested on WRN-28-10:
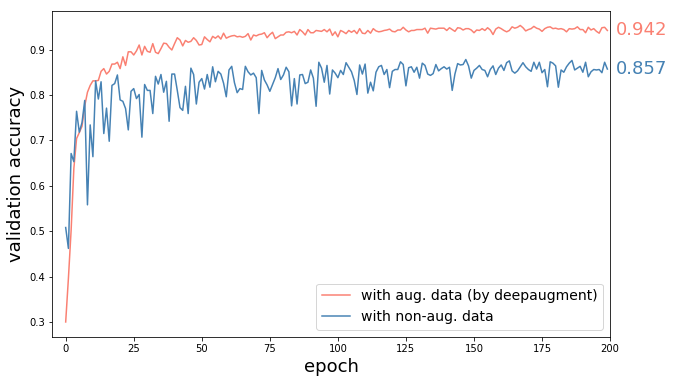

Result: 60% reduction in error (8.5% accuracy increase) by DeepAugment