How It Works¶
Technical deep-dive into DeepAugment’s design and methodology.
Overview¶
DeepAugment automates the search for optimal image augmentation policies using Bayesian Optimization. It consists of three main components that work together in an iterative loop:
Controller: Samples augmentation policies using Bayesian Optimization
Augmenter: Transforms images according to policies
Child Model: Evaluates policy quality through training

The Optimization Loop¶
The core workflow:
1. Controller samples a new augmentation policy
2. Augmenter applies the policy to training images
3. Child model trains on augmented images
4. Validation accuracy is computed (reward)
5. Controller updates with (policy, reward) pair
6. Repeat until convergence or max iterations
This process discovers which augmentation combinations work best for your specific dataset.
Why Bayesian Optimization?¶
Comparison of Hyperparameter Optimization Methods¶
Method |
Iterations Needed |
Computation Cost |
Accuracy |
Complexity |
|---|---|---|---|---|
Grid Search |
Very High |
Very High |
Medium |
Low |
Random Search |
High |
High |
Medium |
Low |
Bayesian Optimization |
Low (~100-300) |
Low |
High |
Medium |
Reinforcement Learning |
Very High (~15,000) |
Very High |
High |
High |

AutoAugment vs DeepAugment¶
Google’s AutoAugment uses Reinforcement Learning:
Iterations needed: ~15,000
Time: Days to weeks
Cost: Requires massive computational resources
Accessibility: Not practical for most users
DeepAugment uses Bayesian Optimization:
Iterations needed: ~100-300
Time: Hours
Cost: ~$13 on AWS for CIFAR-10
Accessibility: Practical for individual researchers and small teams
Performance: Bayesian Optimization achieves comparable or better results with ~100x fewer iterations.
Bayesian Optimization Details¶
How It Works¶
Bayesian Optimization maintains a surrogate model that predicts the quality of unexplored policies:
Build surrogate model from previous evaluations
Acquisition function identifies promising policies to try next
Evaluate the selected policy
Update surrogate model with new result
Repeat
DeepAugment uses:
Surrogate: Random Forest Estimator
Acquisition: Expected Improvement (EI)
Library: scikit-optimize
Expected Improvement¶
The acquisition function balances:
Exploitation: Try policies similar to current best
Exploration: Try unexplored regions of policy space
This balance is key to efficient optimization.
Mathematical Formulation¶
The optimization problem:
Where:
\(\\mathbf{p}\) is an augmentation policy
\(\\mathcal{P}\) is the space of all possible policies
\(f(\\mathbf{p})\) is the validation accuracy with policy \(\\mathbf{p}\)
\(\\mathbf{p}^*\) is the optimal policy
The challenge: \(f(\\mathbf{p})\) is expensive to evaluate (requires training a model).
Bayesian Optimization efficiently explores \(\\mathcal{P}\) by building a probabilistic model of \(f\).
Policy Representation¶
Policy Structure¶
A policy consists of \(N\) operations (default \(N=4\)):
Where:
\(t_i\) is a transform type (categorical: 1 to 26)
\(m_i\) is magnitude (continuous: 0.0 to 1.0)
Example policy:
[
('rotate', 0.8), # t₁=rotate, m₁=0.8
('brightness', 0.5), # t₂=brightness, m₂=0.5
('blur', 0.3), # t₃=blur, m₃=0.3
('flip_h', 0.9), # t₄=flip_h, m₄=0.9
]
Search Space Size¶
For \(N=4\) operations with 26 transforms:
Categorical dimensions: 26 choices × 4 = \(26^4 = 456,976\) combinations
Continuous dimensions: \([0, 1]^4\) (infinite)
Total: Extremely large search space
This is why naive grid search is infeasible and Bayesian Optimization is necessary.
Transform Library¶
DeepAugment includes 26 modern transforms from torchvision v2:
Geometric Transforms (8)¶
rotate: Rotation by angleflip_h: Horizontal flipflip_v: Vertical flipaffine: Affine transformationshear: Shear transformationperspective: Perspective transformationelastic: Elastic deformationrandom_crop: Random cropping
Color Transforms (5)¶
brightness: Brightness adjustmentcontrast: Contrast adjustmentsaturation: Saturation adjustmenthue: Hue adjustmentcolor_jitter: Combined color jittering
Advanced Color (7)¶
sharpen: Sharpeningautocontrast: Auto contrastequalize: Histogram equalizationinvert: Color inversionsolarize: Solarizationposterize: Posterizationgrayscale: Grayscale conversion
Blur & Noise (2)¶
blur: Gaussian blurgaussian_noise: Additive Gaussian noise
Occlusion (2)¶
erasing: Random erasingcutout: Cutout augmentation
Advanced (2)¶
channel_permute: Channel permutationphotometric_distort: Photometric distortion
Each transform’s magnitude is normalized to [0, 1] for uniform optimization.
Child Model¶
Architecture¶
The child model is a lightweight CNN designed for fast training:
Parameters: 1,250,858 (for 32×32 images)
Training time: ~30 seconds per iteration on V100 GPU
Architecture: 3 convolutional blocks + fully connected layers

Design Principles¶
The child model is intentionally small:
Fast evaluation: Each policy needs training from scratch
Good proxy: Performance correlates with larger models
Memory efficient: Fits in GPU memory with large batches
Key insight: Small model + good augmentation ≈ Large model + weak augmentation
Custom Models¶
You can use your own model as the child model:
aug = DeepAugment(
X_train, y_train, X_val, y_val,
model=MyCustomModel
)
Trade-off: Larger models give more accurate policy evaluation but take longer.
Reward Function¶
Default Reward¶
The reward is the validation accuracy of the child model trained with the policy:
Implementation details:
Model trained for \(E\) epochs (default \(E=10\))
Reward is mean of top \(K\) validation accuracies (default \(K=3\))
This reduces noise from training variance
Custom Rewards¶
You can define custom reward functions:
def my_reward(entry):
score = entry['score']
policy = entry['policy']
# Example: Penalize complex policies
complexity = len(policy)
return score - 0.01 * complexity
aug = DeepAugment(
X_train, y_train, X_val, y_val,
custom_reward_fn=my_reward
)
This allows optimizing for multiple objectives (accuracy + simplicity, speed, etc.).
Data Pipeline¶
Training Data Flow¶
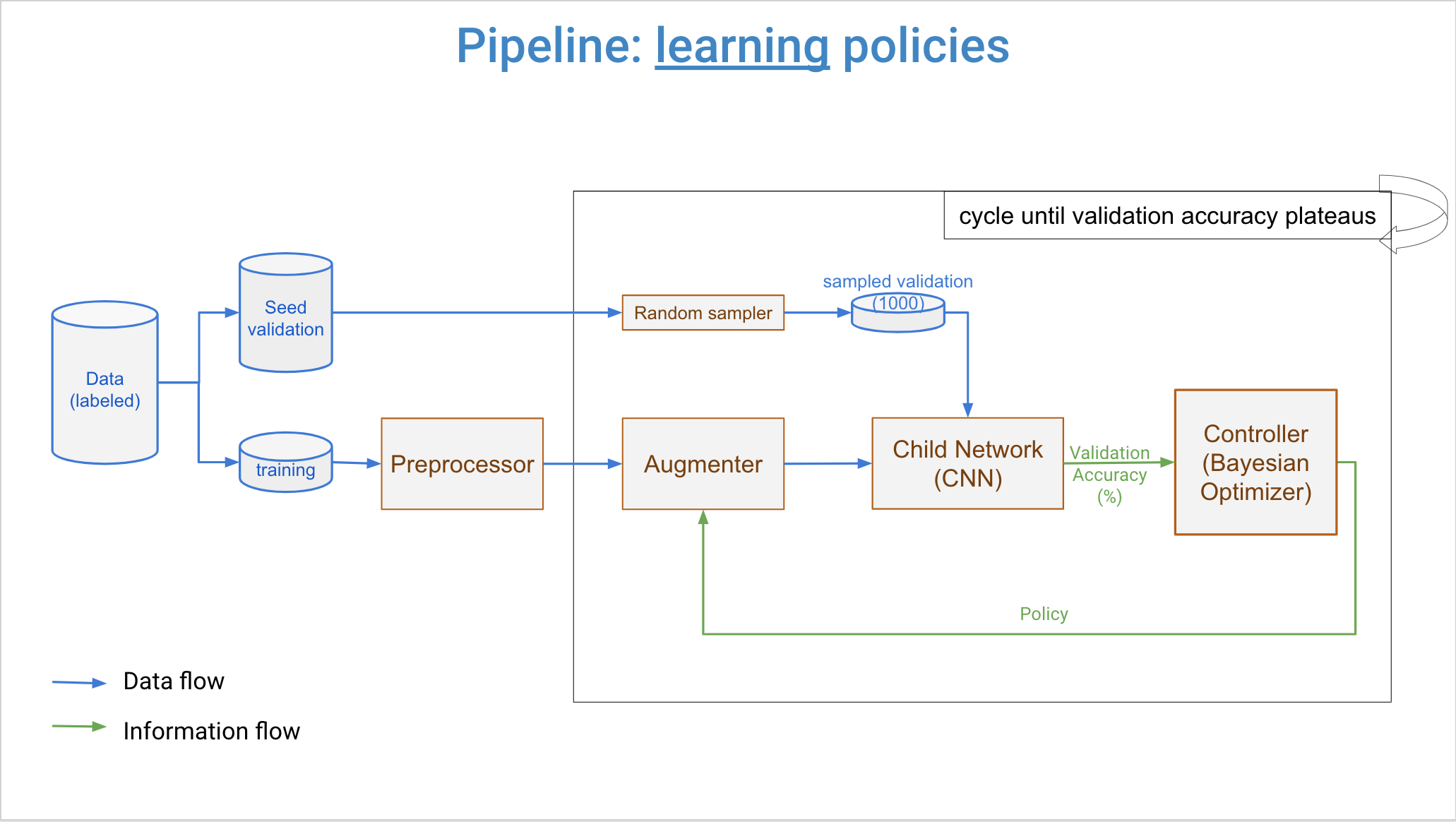
Validation Data Flow¶

Key Points¶
Augmentation applied per-epoch: Same image gets different augmentations each epoch
Validation not augmented: Ensures unbiased evaluation
Random sampling: Magnitude determines probability/intensity of each transform
Sequential application: Transforms applied in policy order
Design Principles¶
DeepAugment follows several design philosophies:
Convention over Configuration¶
Sensible defaults for everything:
# This works out of the box
best = optimize(X, y, iterations=50)
Rails Doctrine¶
Optimize for programmer happiness: Clean API, readable code
Convention over configuration: Defaults work well
Progress over stability: Use modern approaches
Omakase: Curated, opinionated stack
Single Source of Truth¶
Each piece of logic lives in exactly one place:
Policy representation →
policy.pyTransforms →
transforms.pyTraining →
trainer.pySearch →
search.py
This makes the codebase maintainable and extensible.
Academic Foundation¶
DeepAugment builds on strong theoretical foundations:
Key Papers¶
AutoAugment (Cubuk et al., 2018): Original idea of learned augmentation
Bayesian Optimization Review (Shahriari et al., 2016): BO theory
Neural Architecture Search (Zoph et al., 2016): Search methodology
Cutout (DeVries & Taylor, 2017): Occlusion augmentation
Novel Contributions¶
DeepAugment’s contributions:
First application of Bayesian Optimization to augmentation policy search
Minimized child model for computational efficiency
Practical implementation accessible to individual researchers
Open source with complete code and documentation
Performance Validation¶
Validated on CIFAR-10 with WRN-28-10:
Baseline: 91.5% accuracy
With DeepAugment: 95.0% accuracy
Improvement: 8.5% absolute (60% error reduction)
See Citation & References for how to cite this work.
Computational Complexity¶
Time Complexity¶
For \(T\) iterations, \(E\) epochs, \(N\) samples, batch size \(B\):
For CIFAR-10 with default settings:
\(T=100\) iterations
\(E=10\) epochs
\(N=2000\) samples
\(B=64\) batch size
:math:`t=0.01`s per batch on V100
Total time: ~4.2 hours (~$13 on AWS p3.x2large)
Space Complexity¶
Memory usage:
Model parameters: ~1.2M × 4 bytes = 5 MB
Batch storage: batch_size × image_size × 4 bytes
Optimizer state: 2× model size = 10 MB
Total: ~100-200 MB on GPU (very efficient)
See Also¶
Citation & References - How to cite DeepAugment
Advanced Usage - Advanced usage patterns
API Reference - API documentation